公開日:
前回の「Amazon Personalize と Forecast を やってみた」では Amazon Forecast の基本的な使い方を習得しました。
ここから Amazon Forecast を実用していけるようになるには、色々なデータを読み込ませ予測の精度を確認・検証する経験を積んでいくしかなさそうです。
今回は Amazon Forecast に用意されている 事前定義済みのデータセットドメイン をいくつか試していこうと思います。
まずは amazon-sagemaker-deepar-retail サンプル の train.csv を読み込ませてみます。このサンプルは Amazon SageMaker を使って 店舗別商品売上の予測 を行うものですが、 Amazon Forecast が登場した今、Forecast を使うと どんな結果が出るか試してみない手はないですよね(笑
商品の売上なので RETAIL ドメイン を選択します。TARGET_TIME_SERIES データセットのスキーマを以下のように指定します。
{
“Attributes”: [
{
“AttributeName”: “timestamp”,
“AttributeType”: “timestamp”
},
{
“AttributeName”: “location”,
“AttributeType”: “string”
},
{
“AttributeName”: “item_id”,
“AttributeType”: “string”
},
{
“AttributeName”: “demand”,
“AttributeType”: “float”
}
]
}
今回は他に予測の材料として Forecast に提供できるデータがないので RELATED_TIME_SERIES や ITEM_METADATA タイプのデータセットは作成せずに AutoML で predictor を作成します。
そして、店舗別の商品売上なので “Forecast dimensions” に location を追加します。これによって商品に加え、店舗という軸を追加して売上を予測出来るようになります。
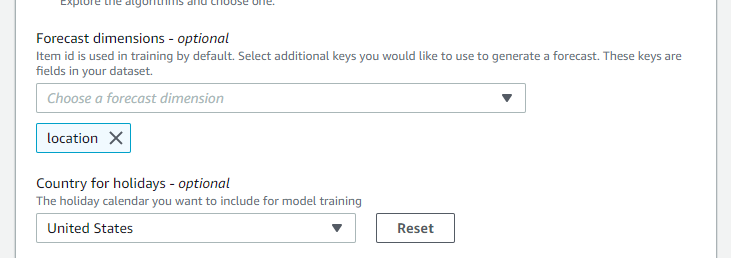
Forecast dimensions で予測軸を追加する
train.csv は 2013/1/1 から 2017/12/31 までの 10店舗(location)、50商品(item)の日別売上データ(913,000件)です。
2018/1/1 から 1/10 を予測させ、特定店舗の特定商品の予測結果を取得します。結果論として、この入力データからは AutoMLで 指数平滑法 (ETS) のアルゴリズムが選択されました。
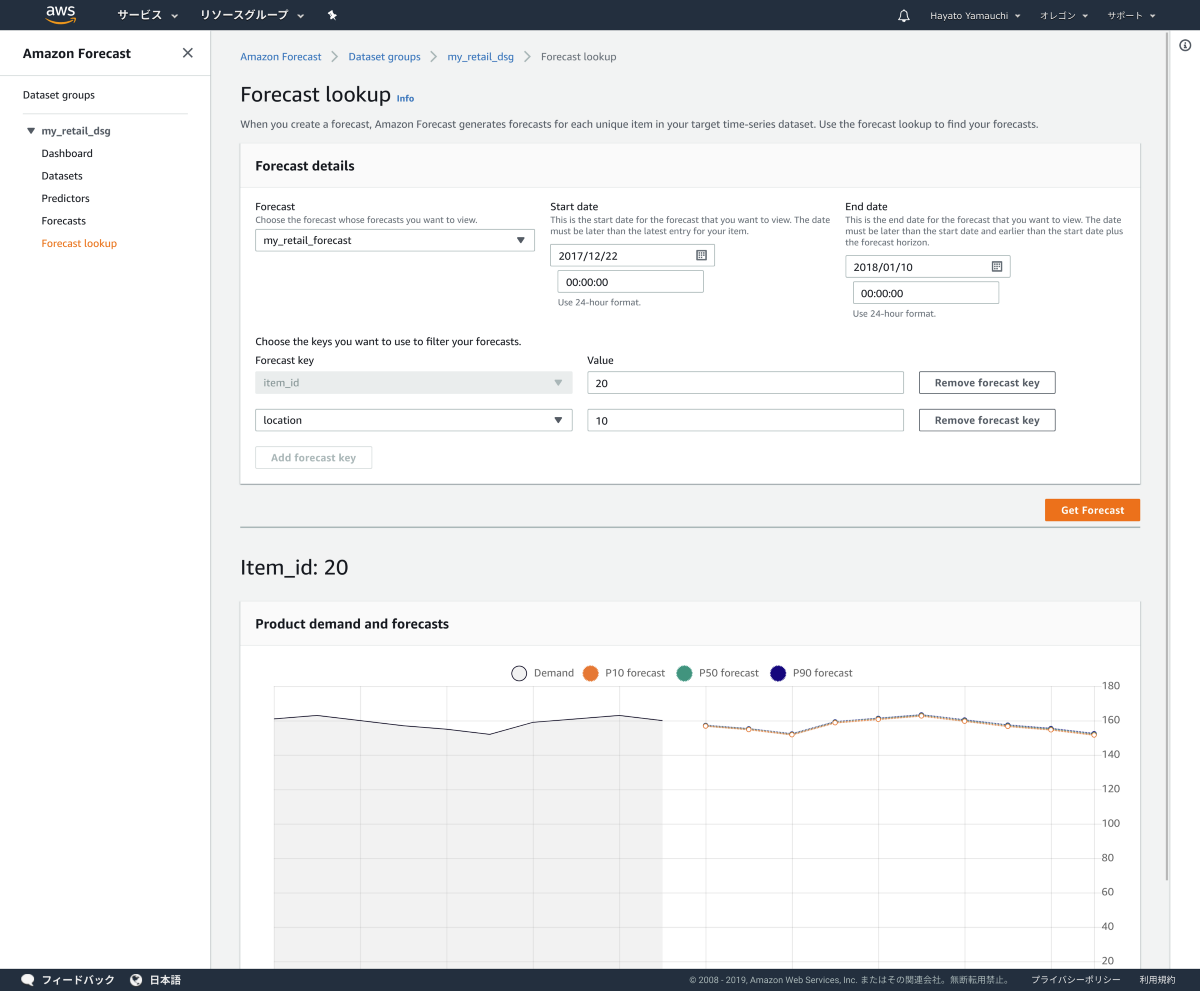
指数平滑法 (ETS) アルゴリズムで売上予測
P10, P50, P90 の 3つの予測結果全てに、ほぼ同じ値が予測されています。
エクスポートした結果を見てみると
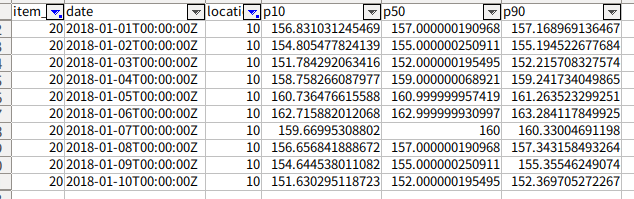
指数平滑法 (ETS) アルゴリズムの予測値
完全に同じではないものの、差が非常に小さいです。
入力データ (train.csv) の 2017/1/1 から 1/10(ちょうど一年前)と比較してみます。
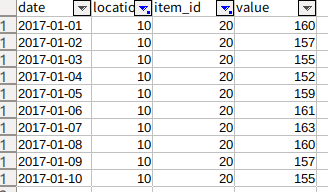
1年前の実績値
こんなものかなあ・・ という感じです。
次は DeepAR+ アルゴリズム を使ってみます。
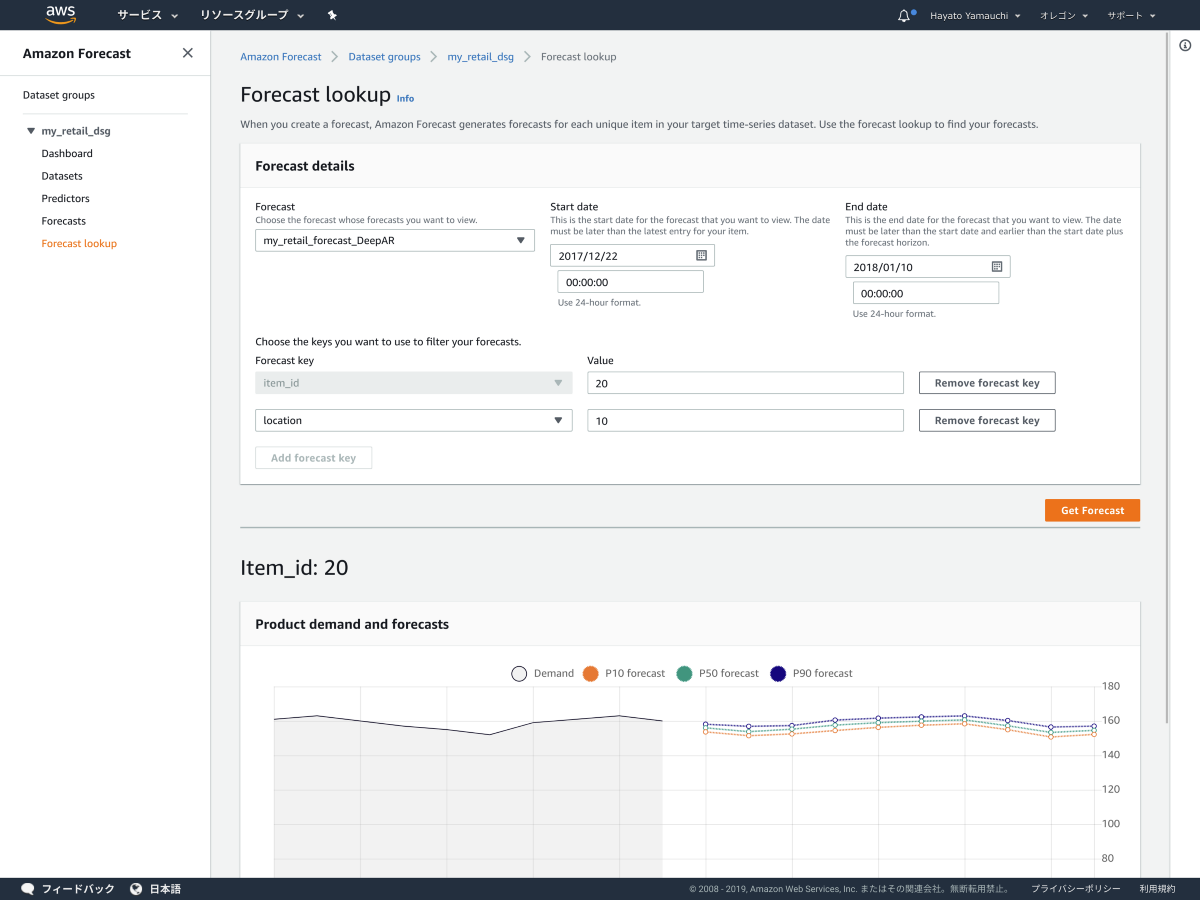
DeepAR+アルゴリズムの売上予測
やっぱり、P10, P50, P90 の傾向が似ています。
AutoML で 指数平滑法 (ETS) が選択されたことからも TARGET_TIME_SERIES データセットだけでは DeepAR+ アルゴリズム の良さを活かしきれないのかなと思いました。
ITEM_METADATA データセットで各商品の種類や類似性を示す値を入れ、RELATED_TIME_SERIES データセットで販売価格、在庫、特売をあらわすデータを入れれば、特徴的な結果を得られるようになるかもしれません。
次に amazon-sagemaker-stock-prediction サンプル の dbg-stockdata/source/D を試します。これはフランクフルト証券取引所で取引されている株式の株式市場データです。一時間単位のデータも用意されていますが、日単位でも Amazon SageMaker の ml.c5.18xlarge インスタンスタイプでモデルのトレーニングに約15分かかるという記述を見てビビったので、今回は特定の銘柄(BMW)だけを読ませることにしました。
(自動車関連株を中心に他の銘柄のデータも読ませた方が精度が上がるのは間違いないですが、今回は我慢します・・)
ドメインは METRICS ドメイン を使ってみます。
終値(EndPrice) の列だけを抜き出して TARGET_TIME_SERIES データセットを作成します。終値(EndPrice) 以外の列は RELATED_TIME_SERIES データセットに入れます。スキーマは以下のようになりました。
{
“Attributes”: [
{
“AttributeName”: “timestamp”,
“AttributeType”: “timestamp”
},
{
“AttributeName”: “metric_name”,
“AttributeType”: “string”
},
{
“AttributeName”: “MinPrice”,
“AttributeType”: “float”
},
{
“AttributeName”: “MaxPrice”,
“AttributeType”: “float”
},
{
“AttributeName”: “StartPrice”,
“AttributeType”: “float”
},
{
“AttributeName”: “TradedVolume”,
“AttributeType”: “float”
},
{
“AttributeName”: “NumberOfTrades”,
“AttributeType”: “float”
}
]
}
今回のデータには 2017/7/3 から 2018/10/25 までが含まれています。
休日分のデータ行は入っていないのですが、現状、RELATED_TIME_SERIES データセットでは欠けた日のないように入力する必要があるようです。さらに Forecast horizon に 10 を指定して 2018/11/02 までの予測ができるように
2018/10/26 以降の値をでっち上げました。(見込み値を入力)
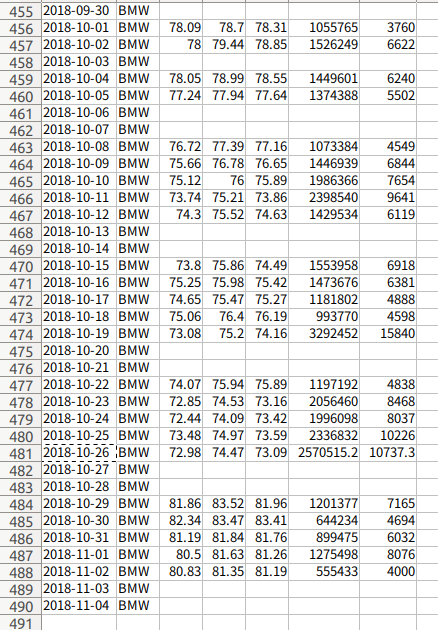
欠けている日を埋め、予測対象日に見込み値を入れた RELATED_TIME_SERIES データセット
AutoML で predictor を作成したら 自己回帰和分移動平均 (ARIMA) が選択されました。予測結果を見てみます。
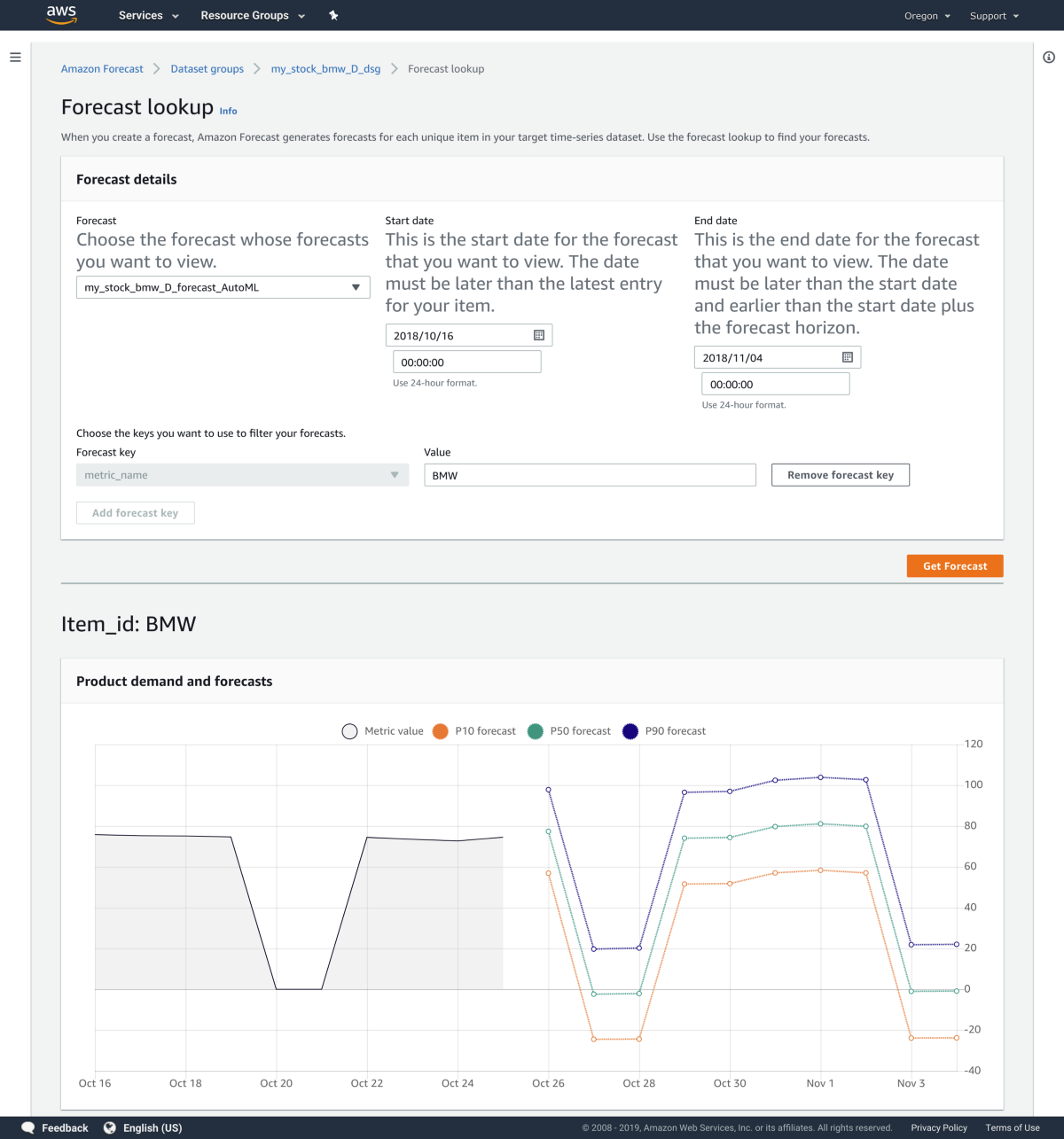
自己回帰和分移動平均 (ARIMA) アルゴリズムによる株価予測
株価がマイナス!? と一瞬思いますが、凹んでいる箇所は土日です。
Country for holidays も指定しているし、株式市場が休日は開いていないことをデータの内容から考慮してほしいところですが、METRICS ドメイン では致し方ないのかもしれません。
(アルゴリズムによっては、ひょっとしたらハイパーパラメータで指定できるかもしれません。)
アルゴリズムに Prophet を指定した場合の結果は以下のようになりました。
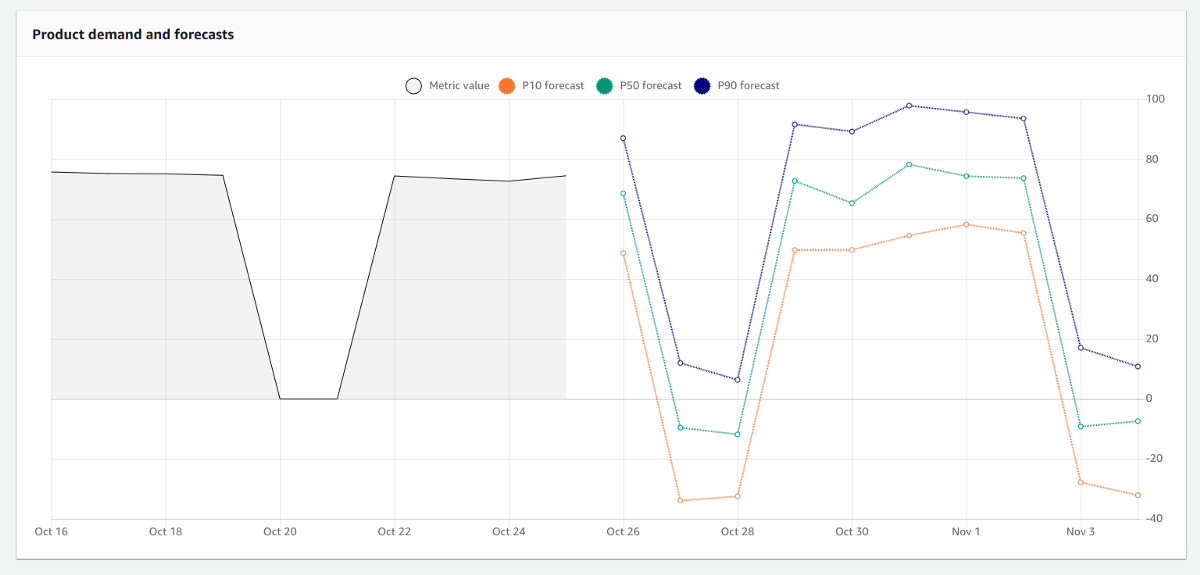
Prophetアルゴリズムによる株価予測
Prophet は Facebook が開発した非常に人気のある時系列予測のオープンソースライブラリのようで、、
と続けようとしたのですが、 Prophet の検証は次の機会にしたいと思います。